This branch contains translations from both Russian and English. The material presented in this branch touches a lot of topics. I just put here everything interesting for me.
<< More recent
Sept 30th 2007
Протеиновые компьютеры
Механизмы, созданные из биологических молекул обещают иметь малый объем и более быстрые устройства памяти. Они дают возможность создания мультипроцессных компьютеров, трехмерной памяти и нейро - сетей.
Наиболее продвинутый в мире компьютер не требует одного полупроводникового чипа. Человеческий ум состоит из органических молекул, скалдывающихся вместе для формирования очень сложной сети, умеющей проводить вычисления, воспринимать, управлять, самовосстанавливаться, думать и чувствовать. Цифровые компьютеры совершенно точно выполняют вычисления быстрее и точнее, чем некоторые люди, однако даже простые организмы являются превосходящими в оставшихся пяти областях. Разработчики компьютеров наверное никогда не смогут создать машины, имеющие способности живого мозга, однако многие из нас могут использовать некоторые специальные свойства биологических молекул - в частности, протеинов - с тем, чтобы построить компоненты, которые меньше, быстрее и более мощные, чем любые электронные механизмы на печатных платах до сих пор являлись.
Проблема размера является наиболее острой. Начиная с 60-х, компьютерная промышленность была вынуждена создавать индивидуальные элементы на полупроводниковых чипах всё меньше и меньше, чтобы производить более объемную память и более мощные процессоры экономичнее. Такие чипы состоят обязательно из массивов переключателей, обычно такого типа, который называется логическими воротами, которые переворачиваются между двумя состояниями - обозначенное как ноль и как один - отвечающие за изменения электрического тока, протекаюшего через них. (Компьютеры обычно представляют всю информацию в терминах таких двоичных чисел или битов.) Если тенденция к минитиарюзации продолжится, то к 2030 году размер одних логических ворот приблизится к размеру молекулы.
Однако существует серъезный тупик: каждое уменьшение размера ворот вдвое увеличивает цену впятеро. Начиная с некоторого момента поиски новых ещё более меньних механизмов будет остановлен экономическими возможностяии, нежели физическими. С другой стороны использование биологических молекул в качесве активных элементов в компьютере может предложить альтернативный подход, являющийся более экономичным.
Молекулы потенциально могут служить компьютерными переключателями, т.к. атомы этих молекул подвижны и изменяют положение предсказуемым образом. Если мы можем руководить атомным движением и соответственно генерировать хотя бы два дискретных состояния в молекуле, мы можем использовать такие состояния как нулевое и единичное. Такие переключатели предлагают уменьшения в размерах железа, потому как они сами очень маленькие - примерно тысячная от размера транзисторов, используемых сегодня( которые составляют примерно микрон или одну милионную метра в диаметре). Действительно, биомолекулярный компьютер может, в принципе, быть в пятьдесят раз меньше сеодняшнего полупроводникового компьютера, собранного из примерно такого же количества логических элементов. В компьютерном бизнесе меньший размер логических ворот способствует скорости механизма, и протеиновые компьютеры могут, теоретически, работать в тысячу раз быстрее, нежели современные компьютеры.
В настоящий момент никто серъёзно не продвигает чисто биомолекулярный компьютер. Более вероятно, по меньшей мере в ближайшем будующем, что будет некая компромиссная технология, в которой полупроводники и молекулы используются вместе. Такой подход может обеспечить уменьше размера в 50 раз и увеличение производительности в 100 раз.
Биомолекулы также притягательны потому как могут быть выполнены в виде одного атома, дающие разработчикам управление, которое им нужно для производства ворот, умеющих работать вточности как нужно приложению. Далее, биоэлектронные компьютеры должны помочь в постоянных поисках более легко приспосабливающихся компьютеров. Компьютерные ученые создали столько архитектур (новых конфигураций)!
Исследователи ввели мультипроцессорные архитектуры, позволяющие параллельную обработку нескольких наборов данных в тоже самое время. Для того, чтобы расширить объем памяти, они разрабатывают железо, которое хранит инфу в трех размерностях вместо обычных двух. А также ученые постоили нейро-сети, которые пародируют способность мозга изучать способом ассоциации, что является необходимой способностью для значительного прогресса в искусственном интеллекте. Возможность определенных протеинов менять их свойства, принимая свет, должно упростить железо, необходимое для воплощения в жизнь этих архитектур.
Хотя и нет компьютерных компонентов, созданных полностью или частично из протеинов, представленных на рынке, продолжающиеся исследования очень успешны. Кажется обоснованным предсказать, что гибридная технология комбинирущая полупроводниковые чипы и биомолекулы перейдет из теории в коммерческое приложение очень скоро. Технология жидко кристаллических мониторов предлагает первоначальный пример гибридной системы, которая достигла коммерческого успеха. Большинство ноутбуков сегодня зависят от ЖКД, которые комбинируют полупроводниковые механизмы и органические молекулы для контроля интенсивности картины на экране.
Несколько биомолекул рассматриваются для использования в производстве компьютерного железа, однако бактериологический протеин бактериородопсин вызвал наибольший интерес. На протяжении последних десяти лет моя лаборатория и другие в Северной Америке, Европе и Японии строят прототип параллельно - обрабатывающего механизма, трёх - мерной памяти и нейро - сети.
Sept 24
Application letter of a pilot (h⁄w)
5, October St
660077 Krasnoyarsk
Russia
Mr. Johny Wing
32407 Atlanta
Georgia
USA
Dear Mr. Wing,
I'd like to have a pilot position at the Delta airlines.
I was born in Russia in 1986. My education is automation of scientific research. After finishing university I moved to Atlanta, Georgia. Finished a pilot faculty at the local university. Then I've been a pilot of goods airplane for almost 10 years. I've still got good physical form. I don't smoke and don't take any drugs. I can speak English good enough to have the job even if all other pilots are foreigners.
I really want this position because I enjoy driving such a big system that the plain is. It's really exciting for me: the machine reacts on every movement you make and you feel it as you are the machine. Wings vibration and air threads - everything in the sky. You can see a lot of places on the Earth even from such a big distance.
It is a kind of riddle for me why I want to fly on passenger airplanes. But I'm sure I can be terrific pilot.
If you take me could you please tell me some details about the job, such as what's my supposed salary or how many hours per week am I supposed to work? What about life assurance and free meals? What kind of flighs will I have - long or short?
Can not wait for a letter from you.
Sincerely yours, Ivan Yurlagin
Apr 5 2007
Failure Trends in a Large Disk Drive Population <snippets>
Краткий обзор. Подсчитано, что более 90% новой информации, получаемой в мире, сохраняется на магнитных дисках, большая часть из которых есть жёсткие диски. Несмотря на их важность, существует относительно мало опубликованных работ по модели сбоев жестких дисков и ключевых факторах, влияющих на их продолжительности жизни. БОльшая часть информации основана или на экстраполяции экспериментов по ускоренному старению или на относительно скромных по размерам исследованиях. Более того, изучения с более серъёзными популяцими редко имеют инфраструктуру, позволяющую собрать сигналы о <здоровье> системы, что является важнйшей информацией для детального анализа сбоев.
Мы представляем данные, собранные из детальных наблюдений больших дисковых популяций в центре Интернет-служб. Обследованная популяция во много раз больше, чем были в существующих публикациях. К тому же для представления статистики отказов мы анализируем корреляцию между сбоями и несколькими параметрами, которые обычно считаются уменьшающими продолжительность.
Нащ анализ идентифицирует некоторые параметры технологии самоконтроля и составления отчетов (технология SMART), которые сильно коррелируют со сбоями. Несмотря на сильную корреляцию, мы заключаем, что модели, построенные на SMART, не кажутся полезными для предсказания индивидуальных сбоев. Удивительно, мы обнаружилиЮ что температура и уровень активности коррелируют намного меньше со сбоями, чем это было заявлено ранее.
Ключевые находки:
Противоположность ранее опубликованным результатам, мы обнаружили очень маленькую корреляцию между процентом сбоев и повышенной температурой или уровнем активности.
Некоторые параметры SMART имеют большое влияние на вероятность сбоя.
Непохоже, что правильная модель предсказания сбоев, может быть построена только на сигналах SMART. Мы получали очень мало сигналов SMART от сдохших винтов.
Инфраструктура системы здоровья (ИСЗ) это большая распределенная программная система, которая собирает и сохраняет сотни пар аттрибут-значение со всех серверов Google, и обеспечивает интерфейс для любого анализа работ, производимых над данными.
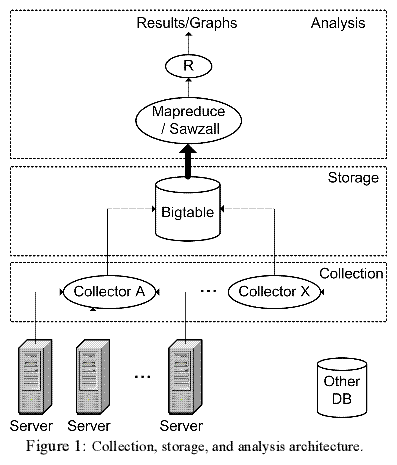 Архитектура ИСЗ показана на рис.1. Она состоит из слоя, собирающего данные, хранилища и фреймворка обработки собранных данных. Собирающий слой ответственнен за получение информации с каждого из тысячи серверов в централизованное хранилище. Существуют много возможностей для сбора различных данных. Большинство информации о здоровье системы собирается напрямую с машин. На каждой машине установлена резидентная программа, собирающая данные, связанные с её здоровьем, такие как переменные среды, информация об использовании различных ресурсов, указания на ошибки и информация о конфигурации системы. Безоговорочно выполняется то, что резидентая программа использует ресурсы очень слабо и не пересекается с приложениями. Один способ добиться этого - использовать сборщики, выполненные на уровне железа.
Архитектура ИСЗ показана на рис.1. Она состоит из слоя, собирающего данные, хранилища и фреймворка обработки собранных данных. Собирающий слой ответственнен за получение информации с каждого из тысячи серверов в централизованное хранилище. Существуют много возможностей для сбора различных данных. Большинство информации о здоровье системы собирается напрямую с машин. На каждой машине установлена резидентная программа, собирающая данные, связанные с её здоровьем, такие как переменные среды, информация об использовании различных ресурсов, указания на ошибки и информация о конфигурации системы. Безоговорочно выполняется то, что резидентая программа использует ресурсы очень слабо и не пересекается с приложениями. Один способ добиться этого - использовать сборщики, выполненные на уровне железа.
База данных о здоровье системы основана на Bigtable (большой таблице), являющейся распределенным хранилищем данных, широко используемом внутри Google, которая сама построена на файловой система Google (ФСГ). Bigtable заботится распределении данных, сжатии, распределением прав на данные внутри хранилища. Оно представляет абстракцию двухразмерной таблицы ячеек данных, с различными версиями времени создания на третьей размерности. Это естественная форма хранения отслеживания значений различных переменных(колонки) для различных машин(ряд). Поэтому база данных здоровья системы аккумулирует полную историю среды, использования, ошибок, конфигурации и событий ремонта в жизни каждой машины.
Анализирующие программы работают на самом верху базы данных здоровья системы, рассматривая информацию с индивидульных машин, добывая данные через тысячи машин. Широкомасштабно-анализирующие программы обычно основаны на Mapreduce фреймворке от Google. Mapreduce автоматизирует механизмы широкомасштабных распределенных вычислений, такие как распределение работы, балансировка загрузки, сбоеустойчивость, позволяет пользователью сфокусироваться только на алгоритмах, составляющих сердце вычислений. Анализируюшая очередь, используемая для этих изучений, состоит из работы Mapreduce, написанной на языке Sawzall, и фреймворка, извлекающего и вычищяющего периодические данные SMART и восстанавливающего данные, относящиеся к дискам для последующей их распечатки.
Детали реализации. Данные, представленные в данной работе, собраны с огромного количества дисков, установленных в различных системах сквозь все сервисы Google. Более сотни тысяч дисков были использованы для представленных здесь результатов. Диски - комбинация последовательных и параллельных интерфейсов ATA уровня потребителей, варьирующихся в скорости от 5400 до 7200 оборотов в минуту, и в объеме от 80 до 400 гигабайт. Все элементы, использованные в данной работе, были введены в эксплуатацию в или после 2001 году. Популяция содержит несколько моделей от самых крупных производителей дисков и как минимум девяти моделей. Данные собирались с декабря 2005 по август 2006.
До введения в оборот, все диски прошли короткое испытание на отказ, который состоял из комбинации стресс-тестов чтения/записи, разработанных для отлавливания проблематичных по сборке и конфигурации винтов. Данные, отраженные в данной работе не включают сбои на этой фазе. Поэтому наши данные должны согласовываться с тем, что наблюдает обычный конечный пользователь, потому что большинство производителей винтов прогоняют их через подобные тесты до выпуска на продажу.
Подготовка данных. Определение сбоя. Прямое определение что представляет собой сбой является сложной задачей. Производители и конечные пользователи часто имеют разную статистику, потому что они по-разному определяют это. Если производители винтов говорят о 2% баговых винтов, пользовательские оценки дают 6%. Elerath и Shah сообщают о 15-60% дисков, рассматриваемых как сдохшие.
С точки зрения конечного пользователя дефектный винт - это тот, который достаточно стойко «плохо себя ведёт» и не подходит больше для службы. Т.к. сбои - это иногда результаты комбинирования компонент (конкретный винт с конкретным контроллером или кабелем). Не секрет, что большое количество сдохших винтов могут рассматриваться как рабочие, если им заменить начинку. Поэтому, наиболее правильное определение, которое мы можем представить для события сбоя в данной работе - это винт считается неисправным, если он был заменен в ходе восстановительной процедуры.. Обратите внимание, что это определение неявно исключает винты, которые были заменены из-за апгрейда.
Т.к. не всегда ясно когда точно винт неисправен, мы считаем время сбоя равным времени замены винта, которое может быть иногда несколько дней после реального события сбоя. Информация может быть потеряна или повреждена в нашей очереди собирателя. Потому требуется некоторая фильтрация данных.
В случаях, когда данные точно фиктивные, вся запись о винте игнорируется. Отлавливание фиктивных данных, как бы ни было, является хитрой задачей. Поэтому мы определяем фиктивные данные просто как отрицательные числа или значения данных, которые являются очевидно невозможными. Например, некоторые винты сообщают температуру больше, чем на поверхности Солнца. Другие показывали отрицательные вращательные энергии. Эти данные считались фиктивными и были удалены. С другой стороны, мы не отфильтровывали какие-либо подозрительные значения SMART сигналов, предполагая что те большие значения указывают на реально плохое состояние винта. Фитрация фиктивных данных уменьшила выборку менее, чем на 0.1%.
Результаты. Использование(нагрузка). Мы ожидали очень сильную корреляцию между высокой нагрузкой и высоким уровнем сбоев. Как бы ни было, наши результаты показывают более сложную картину. Во-первых, только самая молодая и самая старая группы показывают такую корреляцию. Трёх-годичники нарушают этот закон.
Одно возможное объяснение - это что если винт не сдох в детстве, то он наименее подозреваем на сбой. Другое объяснение - это что прошлые исследования базировались на экстраполяции экспериментов ускоренного старения.
Apr 3 2007
[Vlad Golovach] UI Design: Self-expression
Passion to self-expression is appeared to be the strongest human nature traits. In most cases people do this by means of things (like moving furniture and purchasing fashionable cloth); in things absence - by singing or whislting graceful songs with lacking pleasant voice. No one can't exist however small period without self-expression.
Average statistical human spends approximately 18 minutes per day in a toilet. This time is pretty enough to call strong desire to express them selves: non-usual toilet paper holder is purchased, walls are painted with relatively unique colors, and the most creative people hang a mirror on a door and so on. It's not suprising that users wanna express them selves at programms they use. Correspondingly, ability to tune a system under one self is appeared powerful reason of subjective satisfaction.
The problem here is that it costs very much. Minimal time is spent for self-expression. Firstly, users are not inclined to be satisfied with first succeed variant (art is a iterative process). Secondly, when new system versions are released (or current version is destroyed by means of redundant self-expression), all should be done from the very beginning. In my very rough estimations this self-expression process takes in average 45 minutes in a week. If agreed with the number it outcomes that one hundred people organization looses 75 hours weekly what equals one work week of a two man.
On the other hand tuned under yours needs interface descends worker tiredness and increases their working mood. In these conditions loss of 45 minutes per week could turn out compensated thanks to improving of labour performance.
Thus in products to be sailed directly to users ability to tune under concrete user is necessary. In all other cases to all appearances tune method allowing to change system apperance at most by means of minimum commands is needed (to descend time for self-expression). Good variant is banal choice of pretuned variant from list without ability to modify fitted variants.
Apr 1 2007
Applied C++: 3.1.2 Выделение памяти
Вместо проектирования объекта, работающего только с изорбажениями, мы создаём общий объект, который можно применять в любом приложении, требующем выделения памяти и управления кучей. Мы преодолели желание сделать совершенный объект, т.к. мы не имеем неограчинно много времени. Коммерческое ПО текуче; важнее спроектировать систему так, чтобы она могла быть адаптируема, расширяема и модифицируема в будущем. Архитектура, представленная здесь, является на самом деле третьим шагом.
Вот список требований для нашего объекта, выделяющего память:
выделяет память на куче, и позволяет использовать свои аллокаторы, выделяющие память в других местах таких как, например, частные кучи.
считает ссылки и удаляет память, когда те больше не нужны.
предоставляет закрывание и открывание как способ управления объектами в мульти - нитевых приложениях (не показано здесь, но включено в ПО на компакт диске. Для рассмотрения деталей смотрите секцию apLock на странице 128).
имеет очень маленькие накладные расходы. Например, нет никаких инициализаций памяти после её выделения. Это оставлено на усмотрение разработчика.
использует шаблоны, поэтому тип для выделения памяти произвольный.
поддерживает простые массивы, [], так же хорошо, как и прямой доступ в память.
выкидывает исключения STL, когда были совершены некорретные попытки доступа в память.
выравнивает начало памяти к началу специфицированной границы. Нужда в этом не очевидна пока Вы не рассматриваете определенные алгоритмы по обработке изображений, которые могут работать лучше, используя знание о расположении объектов в памяти. Некоторые компиляторы, такие как Microsoft Visual C++, могут контролировать выравнивание выделения памяти. Вы включаем эту фичу платформо - независимо.
Прежде чем мы продвинемся вперед с нашим объектом выделения памяти, было бы умно посмотреть может быть существуют готовые решения.
STL всегда является хорошим источником для решений. Вы можете представить где std::vector, std::list или даже std::string может быть использован для управления памятью. Каждый имеет свои бонусы, но ничто из этого не предоставляет подсчёт ссылок. И если даже вопрос подсчёта ссылок не был задачей, есть вопросы по производительности. Каджый из этих шаблонов предоставляет быстрый произвольный доступ для наших данных о пикселях, но они так же оптимизированы для вставки и удаления данных, что нам не нужно.
Почему подсчёт ссылок необходим? Наше решение - создать общий объект, который использует подсчёт ссылок для разделения и автоматического удаления памяти, когда закончили использовать. Подсчёт ссылок позволяет различным объектам разделять однуи ту же информацию. 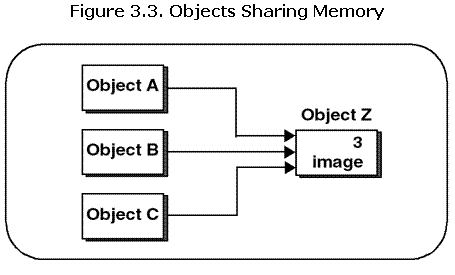 Рисунок 3.3 показывает три объекта, разделяющие изображение из одного и того же места в памяти.
Рисунок 3.3 показывает три объекта, разделяющие изображение из одного и того же места в памяти.
На рисунке объект, содержащий изображение, Object Z так же содержит счётчик ссылок, который указывает сколько объектов разделяют данные. Objects A, B и C - все разделяют одно и тоже изображение.
Рассмотрим следующее:
apImage image2 = image1
Если здесь использовать подсчёт ссылок в этом примере, image2 будет разделять ту же самую память с image1. Если image1 и image2 указывают на одну и туже память, то требуется некое счетоводство для обеспечения уверенности, что данные корректные.
Соль в следующем. Наш объект выделяет память для изображения. Когда последующие изображения нуждаются в разделении этой памяти, объект увеличивает счётчик ссылок; затем он возвращает указатель на себя(выделятор). Когда какое-нибудь изображение удаляется, счётчик уменьшается. Когда счётчик уменьшается до нуля, память освобождается. Давайте взглянем на выделятор apAlloc<>
apAlloc<int> array1 (100);
int i;
for (i=0; i<100; i++)
array1[i] = i;
apAlloc array2 = array1;
for (i=0; i<100; i++)
array1[i] = i*2;
Однажды создав выделятор apAlloc<>, используем его как указатель. В этом примере, мы создаем объект array1 с данными. После присваивания этого объекта объекту array2, код изменяет содержимое array1. array2 теперь содержит то же самое, что и array1. Счётчик ссылок не новое изобретение и очень много дискуссий по его использованию.
Mar 31 2007
Applied C++: Как пользоваться книгой
Считается, что Вы будете читать книгу последовательно, т.к. во второй главе приведен конкретный пример, который используется для конечного рассмотрения в главе 5. На протяжении книги мы выделяем техники, завляенные в заглавиях и выводах, появляющихся на первой странице каждой главы.
Глава 1, Введение, содержит обзор того, что мы наметили выполнить в этйо книге. Мы также снабжаем дополнительные главы по цифровым изображениям. Если Вы имеете опыт работы с приложениями, специализирующимися на изображениях, то наверное захотите пропустить последнуюю секцию этой главы.
Глава 2, Тестовое приложение, знакомит нас с примером не совсем адекватного приложения, являющегося фундаментом, демонстрирующим техники С++. Мы сознательно создали такое поразительно простое приложение, потому что оно эффективно демонстрирует варианты использования различных техник и реализаций этих техник.
Глава 3, Архитектурные техники, начинают наше обсуждение техник С++. Мы используем большое количество примеров кода для демонстрации методик, и мы приводим один пример на шаблонах, т.к. их трудно впихать в книгу. Наконец, мы имитируем различные аспекты разработки основных утилит для поддержки архитектуры.
Глава 4, Разбор техник, обозревает рекомендации и дополнительные стратегии, которые возможно Вы захотите использовать в своей архитектуре. Мы предлагаем практический набор рекомендаций к кодированию, переиспользуемых стратегий и простую, но эффективную стратегию отладки.
Глава 5, Разбор системы, рассматривает архитектурные проблемы на уровне системы, такие как много - нитевые и много - процессные архитектуры, обработка исключительных ситуаций, проблемы времени компиляции и времени исполнения, специализацию шаблонов, и идеи интернализации.
Глава 6, Разбор реализации, применяет техники С++, которые мы успели рассмотреть, для конечной реализации во всех частях фреймворка. В дополнение эта глава вводит глобальные функции обработки цифровых изображений, и снабжает как визуальный обзор так и реализацию на С++. Мы также снабжаем высокоуровневый интерфейс для библиотек и других разработчиков. Особенно мы знакомим Вас с библиотекой примитивов оптимизации для платформ Intel и показываем как их использовать в таких приложениях.
Глава 7, Тестирование и производительность, даёт рациональную стратегию интеграции тестирования модулей в Вашем цикле отладки ПО, включая полный тест фреймворка и обсуждения как это можно расширить для Ваших конкретных нужд. Мы так же упоминаем про производительность, давая специальные техники, которые Вы можете использовать для немедленного улучшения производтельности времени исполнения Вашего приложения.
Глава 8, Продвинутые темы, обозревает те вопросы, о которых мы беспокоимся более всего, такие как копирование при записи, кэширование, использование ключевого слова explicit, const и передача по ссылке. Мы так же включаем секцию по расширению фреймворка Вашими функциями. Мы выделяем процедуры, очень улучшающие обработку Ваших цифровых фотографий.
Дополнение А, Полезные Онлайн Ресурсы, предоставляет ссылки на те утилиты и ресурсы, которые нам кажется могут помочь Вам.
Дополнение Б, Информация о компакт диске.
Mar 30 2007
The C++ In-Depth Series
«Я написал это письмo длиннее, чем обычно, потому что у меня не было времени сделать его коротким».
-- Блез Паскаль
Появление ANSI/ISO стандарта C++ отметило начало новой эры C++ программистов. Стандарт предлагает много новых удобств и возможностей, но как может реальный программист найти время на открытие таких маленьких мудростей внутри обрушивающегося потока информации? The C++ In-Depth Series минимизирует время изучения путём рассмотрения убеждающих и точных примеров на соответствующие темы.
Каждая книга из этой серии представляет единственную тему на технически подходящем уровне. Практический подход серии разработан таким образом, что он выносит профессионалов на следующий уровень возможностей. Написанные экспертами в области, эти короткие и глубокие монографии могут быть прочитаны использованы в качестве ссылки без отвлечения к неотносящемуся к делу материалу. Книги внутри серии имеют взаимные ссылки, а также ссылки на Язык программирования С++ Бьярна Страуструпа.
Развивая свои возможности в С++, возрастает важность умения отделять важную информацию от рекламы и блеска, а также находить то, в чем нуждаетесь именно Вы. The C++ In-Depth Series снабжают инструментами, идеями, техниками и новыми подходами в С++, которые выведут Вас на передний край возможностей.
Введение. Эта книга о применении С++ для решения проблем, присущих коммерческому ПО. Те из вас, кто имели опыт работы в разработке сложного ПО, знают о чем мы говорим.
Коммерческое ПО поставляется пользователям(внутренними внешним), которые полагаются на предоставляемый интерфейс. Это может быть во внедренной системе или библиотека или приложение для стандартных платформ. Не имеет значения где в конечном счете это работает, ПО должно быть выпущено в заданное время со всеми запланнированными возможностями. Инженеры, поддерживащие это ПО, могут не состоять в команде первоначальных разработчиков, и они могут захотеть добавить возможности или устранить некоторые неполадки.
Отбор команды инженеров для разработки сложной подсистемы ПО и поставка ПО к сроку с полной функциональностью есть одна из наиболее сложных задач. Ещё большая задача - это разработка ПО таким образом, что оно может быть отдано другим разработчикам для расширения функциональности и сопровождения. Техники С++ и практические советы, которые мы включили в книгу, были много раз использованы для выполнения именно этого. Во многих случаях мы показываем отличия между идеальным решением и настоящим. Мы пробуем предлагать альтернативные решения так, что Вы можете выбрать свой, оригинальный и заточенный способ, а также сообщаем Вам наш критерий, когда выборирать один метод вместо другого. Мы оставляем выбор наиболее лучшего метода для Вашего ПО за Вами. Наша цель - поделиться практическими техниками, которые мы обнаружили наиболее эффективными для наших программ. Надеемся, что Вы найдёте их полезными.
Для тех и вас, кто предпочитает изучать, смотря в код, Вы найдёте кучу примеров. Мы иллюстрируем технику рассмотрением конкретного римера сквозь всю книгу. Т.к. нашим опытом была область разработки ПО для обработки изображений, то примеры идут как раз оттуда. Однако техники С++ применимы к любой области.
Мы начинаем с простого, хотя и неадекватного, приложения, генерирующего миниатюры для изображений. Мы используем это приложение в нашей фазе прообраза для экспериментирования с разными техниками С++. Приложение простое для понимания и результаты применения различных техник С++ очевидны.
Этот простой миниатюро-генератор, имеет множество присущих проблем, которые наш конечный фреймворк встретит. Приложение:
интенсивно использует память. Работа с несколькими изображениями требует эффективного использования памяти, т.к. изображения быть очень большими. Управление памятью становится критическим для производительности приложения.
производительно. Генерирование миниатюр - прямая техника обработки изображений. Остальные представленные позже в книге требуют глубоких техник для обеспечения их удобности. Очень здорово иметь хорошие функции обработки цифровых изображений, но они бесполезны, если слишком долго выполняются.
В итоге Вы будете иметь фреймворк обработки цифровых изображений и практический набор инструментов для С++. Фреймворк обеспечит эффективное хранение изображений и использования памяти, процедуры обработки, интерфейсы для третье-сторонних разработчиков и много оптимизаций производительности. Это будет полезным ПО, имеющем практические техники реализации, так что вы даже можете использовать это в качестве базы для коммерческого ПО.
Полный исходный код миниатюро-генератора, прототипы и фреймворк может быть найден на вложенном компакт диске. Обновления брать с www.appliedcpp.com.
Mar 24 2007
Eric Gamma: Design patterns. (Appendix B: Notation explanation)
Throughout whole book we use diagrams to illustrate important ideas. Some diagrams are irregular: e.g. screenshot, where dialog window or sketchy imagery of object tree is displayed. But under design patterns descriptions to denote relashionships and interplays between classes and objects more formal notation is applied. In the appendix the notation is examined detailed.
We use three diagram types:
at class diagrams classes are represented, its structure and static relations between it;
at object diagrams object structure under runtime is showed;
at interplay diagrams request flow between objects is represented.
In every pattern description there is at least one class diagram. Rest will be used if there is a need. Class and object diagrams are based on Object Modeling Technique (OMT). Interplay diagrams are borrowed from Objectiry methodology and Booch method.
Class diagram. On picture B.1a OMT notation of abstract and concrete classes is represented. Class is denoted as rectangle with the name typed in bold on at top. Basic operations are listed under the name. All copy variables are placed under operations. Information about type isn't necessary; we use C++ syntax placing type name before operation name (for return value type dontion), copy variable or real parameter. Italics serves to indicate class or operation to be abstract.
At some pattern applying it's useful to see where client classes refer to participant classes. If pattern includes client class as one of participants (it means that some functions are layed on client), client is represensted as regular class. For instance time-server. If client isn't in participant list (i.e. don't carry any duties), its representaion is all the same useful because it makes clear an interplay method between participants and clients. In this case client classes are represented with faint font as it showed at B.1b. Substitute could be considered as the example. Faint font is also reminds about we specially didn't include client into participant composition.
At B.1c relations between classes are showed. In OMT notation to denote class inheritance a triangle is used directed from subclass (LineShape at scheme) to parent class (Shape). Reference to object representing aggregation relation «part of a whole» is denoted as line with arrow and rhomb at the end. Arrow indicates aggregated class (e.g. Shape). Line with arrow without rhomb denotes knowledge relation (like LineSpahe contains link to Color object, which could be used by another shapes). Near the beginning of the arrow the link name could be placed allowing to differ it from another links.
One more useful property to visualize is which classes create copies of another classes. Dashed line is used for it because OMT doesn't support relation like this. We call that realion «creates». Arrow is directed to class copy to be instanciated. At B.1c CreationTool class creates copies of LineShape objects.
In OMT filled circle symbol is also defined denoting «more than one». If that circle appears near arrow it tells that the arrow refers to several objects or that several objects are aggregated. At B.1c showed that Drawing class aggregates several objects of Shape type.
Finally we expanded OMT with annotations on pseudo-code, which allow to describe operations implementation in a short way. At B.1d annotation like this is brought for Draw operation in Drawing class.
Object diagram. At object diagram there are only copies. Objects snap shot in a pattern is displayed on the diagram. Objects are named as «aSomething», where Something is a object class. For class object denotion a rectangle with rounded corners is used (what differs from OMT standart a little bit) where object name is separated from references to another objects by a horizontal line. Arrows lead to objects to which current object refers. At B.2 corresponding example is represented.
Interplay diagram. Order of queries performing which objects send to each other is represented at interplay diagram. So at B.3 represented how shape is added to picture.
At interplay diagram time is counted out upside down. Solid vertical line denotes object lifetime. Convention about naming is the same as at object diagrams: before class name there is letter 'a' (e.g. aShape). If object isn't created by the beginning time represented at diagram its vertical line painted dashed till moment of creation.
Vertical rectangle says object is active, i.e. some query is performed. Operation can send queries to another objects, it's displayed by horizontal line indicating the receiver object. Query name is displayed over arrow. Query to object creation is represented by dashed line with arrow. Query from sender object to itself is displayed by arrow pointing to itself.
At B.3 could be seen that first query coming from aCreationTool pursues creation of aLineShape object. Then aLineShape is added to aDrawing object by means of Add operation, then aDrawing sends query to itself to make a Refresh. Note that part of Refresh operation is dispatching query to aLineShape by aDrawing.
Mar 24 2007
Extreme Programming. Eric Gamma.
Введение. Экстремальное программирование (ЭП) выдвигает кодривароние как ключевую активность на протяжени всего софтверного проекта. Возможно это не правда!
Время рассказать немного о моей работе разработчика. Я работаю в софтверной культуре точно в момент, когда понадобилось с сжатыми циклами релизов, приправленными высоким техническим риском. Умение менять друзей является Вашей способностью выживать. Общение с часто географически разбросанными командами осуществляется посредством кода. Мы читаем код, чтобы понять новую систему API(прикладной программный интерфейс). Жизненный цикл программ и поведение сложных объектов определяется в тестовых примерах опять же в коде. Наконец, мы постоянно улучшаем существующий код. Очевидно наша разработка сфокусирована на код, но мы успешно доставляем софт вовремя, поэтому это все таки работает.
Было бы неправильно подытожить, что всё что нужно для разработки софта вовремя это безрассудное программирование. Разработка софта сложна, и разработка качественного софта ещё сложнее. Чтобы заставить это работать надо применять дополнительные проверенные методы. Это с чего Кент начинает его мозго-возбуждающую книгу по ЭП.
Кент был среди лидеров в Тектрониксе(Tektronix) для осознвания человеческого потенциала в парном программировании (loop pair programming) в Smalltalk для сложных инженерных приложений. Вместе с Вордом Кунингом (Ward Cunningham) он вдохновил шаблонное движение, которое возымело огромное влияние на мою карьеру. ЭП описывает точку зрения разработки, которая комбинирует практики, использованные многими успешными разработчиками, которые прокопали массу литературы о софтверных методах и процессах. Так же как и шаблоны, ЭП основывается на лучших практиках таких как: тесты модулей, парное программирование и рефакторинг. В ЭП эти практики комбинируются таким образом, что они дополняют и контролируют друг друга. Смысл во взаимодействии разных практик. Существует единственная цель - клепать софт с правильной функциональностью и короткими датами.
Я получил кайф от моего взаимодействия с Кентом и от практикования ЭП при разработке маленькой штуки Junit. Его видение и подходы всегда оспаривали мои подходы в разработке ПО. Нет сомнений, что ЭП ставит под вопрос некоторые подходы традиционного большого М; эта книга позволит вам решить пользовать ЭП или нет.
Предисловие. Эта книга об ЭП. ЭП это легковесная методология для малых и средних разработчиских команд перед лицом нечетких или быстро меняющихся требований. Эта книга направлена помочь Вам решить подходит ли Ваи ЭП.
Для некоторых ЭП означает просто типа здравого смысла. Так почему же «экстремальное»? ЭП берёт принципы здравого смысла и применяет их в экстремальных условиях.
Если просматривать код постоянно (парное программирование), тогда тестирование успешно.
Если все постоянно тестируют (модульное тестирование), даже пользователи (функционально тестирование), то тестирование успешно.
Если каждый считает своим ежедневным делом дизайн(в общем смысле, refactoring), то дизайн успешен.
Если мы оставляем систему с наипростейшим дизайном, поддерживающим текущую функциональность, то простота успешна.
Если все будут работать над определением и очисткой архитектуры все время(метафора), то архитектура успешна.
Если мы интегрируем и тестируем несколько раз в день(непрерыная интеграция), то интеграционное тестирование будет успешным.
Если мы делаем итерации по-настоящему короткими - секунды и минуты и часы, а не недели и месяцы и годы(планирующая игра), то короткие итерации будут успешными.
Когда я впервые сформулировал ЭП, я получил внутрений образ узлов на панели управления. Каждый узел был практикой, которая работала отлично, судя по опыту. Я нашел 10 узлов, и увидел, что произошло. Немного был удивлен, когда обнаружил, что весь набор практик был устойчивым, предсказуемым и гибким.
ЭП делает два набора обещаний.
Для программистов ЭП обещает они будут способны работать над вещами, которые реально имеют значение, каждый день. Они не столкнуться лицом к лицу с устрашающими ситуациями в одиночку. Они будут способны делать всё возможное, чтобы сделать их систему успешной. Они будут делать наилучшие решения и не будут делать плохих ( :) - прим. пер. ).
Потребителям и менеджерам ЭП обещает, что они получат наибольшую пользу от каждой недели программирования. Каждую неделю они будут видеть конкретные результаты по целям, которые их интересуют. Они смогут менять направление проекта в середине разработки без непомерных цен за это.
Короче, ЭП обещает (мир во всем мире - прим. пер.) уменьшить риск проекта, улучшить способность к реагированию по отношению к изменению дел, улучшить продуктивность на протяжении всей жизни проекта, и добавить веселья в построении софта и командах - и все сразу. Правда. Теперь прочитайте остаток книги, чтобы проверить, может я сумасшедший.
Эта книга. Эта книга рассказывает про мышление ЭП - его корни, философию, истории и мифы. Помогает сформировать осведомленное решение пользовать ЭП или нет в Вашем продуктивных программистов. Короче, ищете больших наград и не боитесь пробовать новые идеи, чтобы получить это. Но если вы собираетесь принять риск, Вы хотите быть уверенными, что Вы не попросту тупы.роекте. Второй целью книги для тех, кто уже юзает ЭП, это продвинуть в понимании дальше.
Это не книга про то, как точно программировать в технике ЭП. Вы не прочтёте здесь о чеклистах (checklists) и не увидите много примеров или историй программ. Для этого Вы можете выйти в инет, поговорить с кем-то.
Следующий шаг одобрения ЭП в руках группы людей (Вы можете быть одним из), которые не удовлетворены разработкой софта, как это делается на текущий момент. Вы хотите лучший путь разработки софта, хотите лучших взаимоотношений с пользователями, хотите более веселых, более устойчивых, более продуктивных программистов. Короче, ищете больших наград и не боитесь пробовать новые идеи, чтобы получить это. Но если вы собираетесь принять риск, Вы хотите быть уверенными, что Вы не попросту тупы.
ЭП говорит Вам делать вещи по-разному. Иногда советы ЭП абсолютно противоположны принятной мудрости. Эта книга написана, чтобы дать причины, по которым Вы должны делать вещи по-другому, если хотите следовать ЭП.
Что есть ЭП? Эп - это легковесный, эффективный, малорискованный, гибкий, предсказуемый, научный, и весёлый путь разработки софта. Он отличает от других методов следующим:
Это скорый, конкретный и непрерывно поддерживаемый из которких циклов.
Это постепенно планируемый подход, который быстро приближается с полным планом развития в течение жизни проекта.
Это возможность гибкого переназначения реализации функциональности в соответствии с меняющимися нуждами дел.
Это уверенность, основанная на автоматических тестах, написанных программистами и потребителями, отслеживать процесс разработки, позволить системе выявлять и ловить дефекты рано.
Уверенность устного общения.
Уверенность эволюционного дизайнерского процесса, длящегося столько, сколько работает система.
Уверенность на плотном взаимодействии программистов с обычными способностями.
ЭП - это порядок разработки софта. Это порядок, т.к. есть определенные вещи, которые Вы должны делать, следуя ЭП. Вы не выбираете писать тесты или нет, вы не не экстримал: конец обсуждения.
ЭП разработан для работы с проектами, которые могут быть построены от двух до десяти программистов, которые не точно сдерживаются супер средой и где благоразумная работа выполнения тестов может быть выполнена за часть дня.
ЭП пугает или злит некоторых людей, которые сталкиваются с этим в первый раз. Как бы ни было, никакие из идей в ЭП не являются новыми. Большинство настолько же стары как и программирование. Есть смысл, в котором ЭП консервативно - все используемые техники опробированы декадами и веками(стратегия управления).
Инновация ЭП в:
складывании всех этих практик под один зонтик.
100% убеждении эти техники были опробированы настолько глубоко насколько это возможно.
уверенности что техники поддерживают друг друга в наибольшей возможной степени.
Достаточно. В Лесолюдях и Горнолюдях антропологист Колин Тёрнбул рисует контрастные картины двух обществ. В горах ресурсы всегда были скунды и люди были на краю голода. Развиваемая ими культура была ужасающей. Матери бросали своих детей для скитания в группах диких детей, как только они имели какой-то шанс выжить. Жестокость, зверство и предательство были правилом.
Наоборот леса имели избыток ресурсов. Люди тратили пол часа в день, выполняя все свои основные нужды. Лесная культура зеркальным образом горной жизни. Взрослые делились с подрастающими детьми, которых обучали и любили пока они не были полностью готовы позаботиться о себе. Если один случайно убивал другого (предумышленные преступления были неизвестны), они изгонялись, но ни куда-то, а в лес и всего лишь на несколько месяцев, и всё равно соплеменники приносили им еду.
ЭП - это эксперимент, который даёт ответ на вопрос &kaquo;Как Вы будете программировать, имея достаточно времени?» Сейчас Вы не можете иметь дополнительное время, потому что это всё таки бизнес, и мы определенно играем, чтобы выиграть. Но если Вы располагаете достаточным количеством времени, то будете писать тесты; Вы будете перестраивать систему, когда выучите что-нибудь; будете разговаривать с коллегами программистами и пользователями.
Такая точка зрения достаточности человечна, не то что безжалостная тяжелая невозможность, продикованные дедлайны, которые выводят столь талантных вне бизнеса. Точка зрения достаточности так же хороший бизнес.
Эта книга написана как если бы Вы и я создавали новую дисциплину разработки ПО. Мы начинаем с тестирования наших базовых предположений относительно разработки ПО. Затем создаем дисциплину. Затем заключаем как это может быть использовано путём вовлечения.
Книга разбита на части:
Пролема - главы с «Риск: Основная проблема» по «Назад к основам» устанавливают проблему, которую пытается решить ЭП и представляют критерий для оценки решения. Эта часть даст Вам общее мировоззрение ЭП.
Решение - главы с «Быстрого осмотра» по «Стратегия тестирования» берут абстрактны идеи первой части в практику конкретной методологии. Эта часть не расскажет Вам как конкретно Вы можете выполнять практики, но скорее расскажет про их общую форму. Обсуждение каждой практики сопоставляет её проблеме из первой части.
Реализация ЭП - главы с «Приём ЭП» по «ЭП в работе» описывает разновидность тем о реализации ЭП - как принять это; что ожидается от разных людей в экстренном проекте, как ЭП выглядит для народа из бизнеса.
Mar 12 2007
Глава 1: Волшебство в лесах и морях
"Это было не далеко отсюда",- сказал старик Вэдсворс, показывая рукой в сторону леса, "где капитан Джон Ловел и его люди встретились с индейцами".
"Кто-нибудь из них убежал?",- спросил Генри, который сидел на своих ногах.
"Немного",- сказал брат Генри Стефан, который знал историю наизусть.
"Парни Ловела были сильно в меньшем количестве",- вступил отец Вэдсворс,"и почти все они были убиты в бою".
Дом отца Вэдсворса стоял на огромном куске земли в Майне, почти что в дикой местности, где индейцы бродили несколько лет раньше.
Большой деревянный дом был новым, потому что отец Вэдсворс построил его после Войны за независимость за Северную Америку.
Отец Вэдсворс имел прекрасные сказки про его приключения в Революцию. Его внуки просили его снова и снова про то, как он вырастил группу ополченцев, как он был пойман британскими солдатами, и как он убежал из тюрьмы. Его истории о Войне казались очень правдивыми, настоящими, потому что он до сих пор носил его трехуголку, сморщенную рубашку, бриджи, белые чулки и башмаки с серебрянными пряжками.
Его приключения с индейцами были наиболее интересны Генри. Отец знал нескончаемое количество историй про индейских вождей и племена, которые однажды жили в Майне. Генри никогда не уставал слушать его.
"Расскажи мне историю про Понд Ловела ещё",- просил он.
Близлежащие леса были довольно безопасными в 1812 году, когда Генри Лонгфеллоу было 5 лет и его брат Стефан был в возрасте 7 лет, но мальчишки могли притворяться, что там было опасно. После слушания отцовских историй они могли бежать сквозь лес и быть ополченцами или скаутами для индейцев.
Генри любил больше всего бродить по лесу в одиночку. Они были загадочными. Ветки шевелились и шептались. Индийские девушки выходили из-за деревьев. Стефан был слишком шумным, чтобы услышать эти воображаемые звуки, которые слышал Генри, или чтобы увидеть воображаемых людей, которых видел Генри.
Старик Лонгфеллоу был почти таким же интересным как и старик Вэдсворс и временами мальчишки тратили часть их летнего времени с ним. Его ферма была поблизости Портланда, где Стефан и Генри могли играть со свежим сеном, собирать дикую землянику, и наблюдать как бабушка Лонгфеллоу сбивает молоко в масло. Они могли помочь привести коров домой из полей.
Наиболее захватывающим для Генри был цех кузнеца, что стоял через дорогу от дома старика Генри.
Кузнец был высокий, сильный человек с большими мускулами на руках и он всегда поворачивался и улыбался, когда видел молодого Генри. "Эй, там!",- мог он сказать. "Хотел бы ты стать кузнецом когда-нибудь?"
"Генри кивал головой да, но он не был уверен, что будет когда-нибудь достаточно силен."
Он смотрел в огонь пока кузнец нагнетал его своими мехами и поднимал облако искр вокруг куска железа. Искры летали повсюду в цехе. Железо раскалялось горячо как огонь, когда оно становилось красным и мягким. Потом кузней молотил его в подкову.
Mar 12 2007
Dreams
Dreams dream to every one. In thousand of years we was trying to prove that this trips in a night closely connected with our daily life.
It's dead certain we know one thing - dreams exist in a own spatially-temporary continuum. Even when our physical nature is in a rest state we continue to live active life practically indistinguishable from daily life. World in which we appear in our imaginings is practically impossible to distinguish from those one in which we stay awake. Moreover in dream it often seems to us that we are surrounded by realilty. Thus every clearly remembered dream presents to us one more inreffutable evidence that our life goes not only in a physical reality. We pass every night from birth till very death in a non-material world.
The ancients said that everyone becomes a creator able to develop one's own real world. And dream interpretation is a method assisting us once and once again to enter into a contact with night imagination genius. We carefully study a sophisticated creative process passing every night deep inside our hearts. Our life fills with new content.
The book will teach you to gain understanding in your dream tricks, to remember all its details, to concentrate on its inner logic. You will be able to come back again and to experience it one more time not leaving daily reality. Dreams will open you its innermost meaning.
You'll get to know how to work with dreams by yourself and in a group, and there are a lot of examples of my own practice to help you in realizing.
Only true interest to the subject and wish to perceive are required for the studies.
I wrote the book because I think dream to be a one of the most exciting miracles of life and hope that you'll be able to open your own night ME with this book and to deepen understanding of yourself.
It's a realy big honor to me that Soviet Union readers can become acquainted with the book.
R. Bosnak //In a dream world.